
A RAG LLM is neither a set of letters randomly generated by a gone-off-the-rails robot nor a newfangled geek-speak expression. It's something way more tangible and groundbreaking. Something capable to push the boundaries of artificial intelligence and profoundly reshape human-to-bot interactions. If you still doubt the AI’s potential in view of its current imperfections, hold on and give it another chance.
In this article, we'll build compelling arguments, solve the abbreviation riddle, and explain how to make algorithms work for the good of your business.

written by:
Alexey Sliborsky
Solution Architect

A RAG LLM is neither a set of letters randomly generated by a gone-off-the-rails robot nor a newfangled geek-speak expression. It's something way more tangible and groundbreaking. Something capable to push the boundaries of artificial intelligence and profoundly reshape human-to-bot interactions. If you still doubt the AI’s potential in view of its current imperfections, hold on and give it another chance.
Contents
Welcome to the Generative AI World!
Breakthrough AI tools have infiltrated millions of devices and turned content generation into a double-click, enthralling game. However, many AI users still have a vague idea of the technology's nature, ascribing to it the functionality it is incapable of (e.g., the ability to think). To make sure you are on the right path, take a look at the definition first:
Artificial intelligence is a computer science field and technology aimed at simulation of human brain capabilities. By leveraging the power of algorithms carefully pre-trained with huge amounts of quality data, AI can deliver personalized experiences, make predictions, detect anomalies, identify objects, and process human language.
Artificial intelligence is no news. It has been actively employed by various industries for decades. But why is it grabbing so much attention now? The reason lies in the significant advancements of large language models (LLMs) — powerful algorithms trained to generate new texts. Together with their multimodal peers (capable of working with images, audio, video, and other sense data), they have given fresh impetus to generative AI tools, especially in the USA (the market size here surpasses $16 billion).
Generative AI (GenAI) is a new-age subset of artificial intelligence that can produce original content in compliance with the prompt set by the end user.
Yes, you've heard us right. Generative AI and traditional AI diverge considerably from each other, which means ChatGPT and Siri are different solutions tech-wise. The table below will help you grasp the gist.
Traditional AI
Generative AI
Concept
Implements specific tasks and is limited by the pre-defined scripts
Implements such knowledge-intensive tasks that involve content creation
Capabilities
Analyzes data and makes conclusions and predictions
Generates new content based on its training data
Use Cases
Recommendation systems, conversational chatbots, predictive analytics, virtual assistants, automation tools
Image/text/video creation and editing, code generation, advanced chatbot development
Examples
Siri, Netflix recommendation engine, Google search
ChatGPT, Midjourney, Google Bard
Why Do LLMs Require Fine-Tuning?
LLMs require constant perfection to answer questions correctly. How exactly is it achieved?
First, you pre-train the models on data masses (taken from websites, e-books, and databases), which allows them to remember spelling, grammar, and general language principles. Although the process is time-consuming and the results are too generic, pre-training lays down the lasting groundwork for further procedures.

After that, you train the models on smaller datasets for the specific use, i.e., fine-tune them. This step also takes plenty of time and effort. Moreover, to enable your GenAI solution to deliver relevant responses, you need to retrain the model each time the input information is updated.
That is exactly one of the reasons why ChatGPT lacks accuracy or relevancy sometimes. Having a 128K context window at its core, even the latest GPT-4 Turbo version won't reveal the ‘Oppenheimer’ movie plot to you, as April 2023 is its knowledge cutoff date. And things can get worse sometimes. In certain cases, when it can't detect that a query is beyond its capabilities, it tends to generate plausibly sounding lies.
RAG LLM Explained
Striving to boost the potential of algorithms and eliminate the flaws in response generation, the brightest tech minds keep pooling their efforts around possible solutions. One of the accomplishments they can boast of at the moment is the RAG approach.
Key Idea
So, what is RAG in LLM development?
Retrieval augmented generation (RAG) is a two-step AI framework that enables LLMs to generate accurate responses by retrieving relevant information from external data sources and augmenting the prompt with it.
RAG is divided into two stages. During the retrieval stage, algorithms analyze the user's prompt and retrieve the required information snippets from external data sources (open internet sources or closed-domain settings). The second stage is dedicated to response generation. The LLM combines the extracted data and the internal knowledge and synthesizes the output based on real-time data and backed by source links.
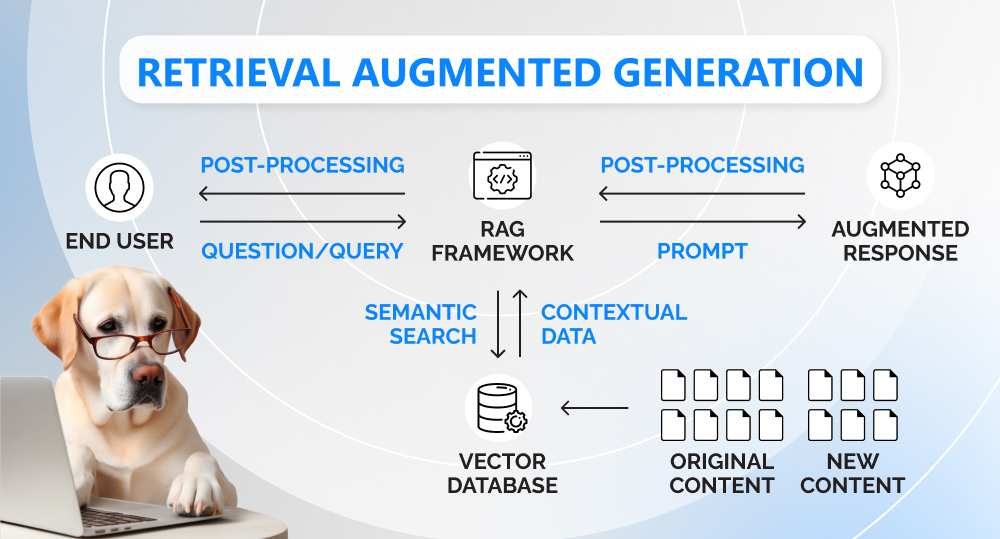
To better understand the process, let's take a look at the following situation.
Imagine the first working day of a new hire who has come to your office. After being introduced to the team and the company's rules, the employee gets down to work. Regardless of the previous experience, the newcomer has multiple questions to ask, as the workflow differs from company to company. To speed up the onboarding process for them, you can either provide extensive answers every time they pick your brain, or create a detailed workflow guidebook and explain to newcomers how to use it.
While the first scenario resembles LLM fine-tuning, when you take a pre-trained foundation model and adjust it to each specific use by training, the second approach can be compared to a RAG pattern (LLM), when you teach algorithms to derive the information from the pre-defined databases. And just like an effective onboarding process requires both strategies, LLMs attain the highest accuracy when combining fine-tuning and RAG.
Data Sources
Now that you know what RAG stands for in the LLM field, it's time to find out what data systems it employs.
To deliver relevant outputs, RAG goes hand in hand with semantic search. Unlike keyword search, it tries to detect the meaning of words and narrow down the query.
If you want to make LLMs extract domain-specific information via semantic search, you’ll need a vector database. It is created by running your proprietary data through an embedding model and turning it into vectors that represent the meaning of the input data.
Embedding models are the key LLM constituents that turn the obtained information into numerical representations, vectors, and arrays, i.e., adjust it to the format a computer can process.

Benefits & Challenges
RAG is a powerful technology that can boost the potential of GenAI. Below, you'll find the list of its current capabilities:
- Response generation based on current, domain-specific information;
- Minimization of LLM hallucinations;
- Great scalability and flexibility, easily achieved by knowledge base extension;
- Cost-efficiency, i.e., no need for constant retraining.
At the same time, since it is a fresh, innovative approach, it still requires further development. Here are the challenges you may face when using RAG for LLM perfection:
- Significant flaws in knowledge bases;
- Repetitions in responses caused by redundant information retrieval.
Food for Thought
According to research by Salesforce, 1,280 out of 4,000 full-time workers across IT, marketing, sales, and service industries still doubt the GenAI tools and even find them useless. However, the technology can already facilitate and optimize many business processes.
For instance, with RAG LLM solutions, you can quickly generate unique content, get market research and financial analyses based on new data, deliver personalized customer experience, write code examples, and provide employees with personalized HR information. And that is just the beginning.
Dreaming of an LLM-powered chatbot capable of extracting exact matches from the text chunks of your business documents and customer records? Turn to Qulix and get a GenAI solution enriched with cross-platform compatibility and advanced analytics.
Valuable Insights
As the notion suggests, retrieval augmented generation (RAG) is the type of architecture that allows a large language model (LLM) to generate responses by retrieving the information from external source documents and augmenting the user's prompt with it.
Without RAG, the LLMs can provide correct answers only if they are pre-trained with relevant scripts. Otherwise, the information output is error-prone or outdated. A RAG LLM architecture eliminates the necessity to constantly update scripts and retrain the models on the latest examples, retaining or even enhancing the answers' quality.
RAG stands for retrieval augmented generation, which means the AI framework that helps to boost the potential of large language models (LLM).
But how exactly does an LLM RAG architecture work? Once the algorithms get customer queries, they start looking for the response in the documents from the knowledge library they have access to using semantic search. To generate the most accurate answer, a RAG LLM model extends the original prompt with the retrieved up-to-date information. Moreover, it can provide citations, source links, or user-specific information (private data).
Large language models or LLMs are the algorithms capable of implementing natural language processing tasks, i.e., they can understand and produce texts.
Retrieval augmented generation or RAG is a framework designed to enhance the capabilities of LLMs by splitting the algorithms' work into two phases (context retrieval and generation) and letting them use an external knowledge base to search for relevant results.
There can be:
- Generalized LLMs (pre-trained foundation models whose answer generation potential is limited by scripts);
- RAG-based LLMs (models that allow for information retrieval from external data sources and provide specific context).
It's hard to compare RAG and an LLM, as these are miscellaneous and equally essential constituents of the GenAI world. However, we can draw a parallel between generalized and RAG-based LLMs and conclude that the latter option is more cost-effective and innovative.
Unlike generalized or pre-trained large language models, LLMs based on RAG can boast higher accuracy and relevance, as they extract answers from credible data sources and provide them to users in a more personalized and efficient manner. Moreover, although the development of RAG LLM bots costs a pretty penny, such solutions prove to be way more budget-friendly in the long run in comparison with their pre-trained counterparts. The reason for such an outcome lies in the necessity to constantly update the scripts for generalized LLMs.
When artificial intelligence employs generative models to create high-quality images, texts, or other content, we are witnessing generative AI in action. This is achieved through the ongoing algorithms' training and enhancement. ChatGPT is the most illustrious example of the solution built with this technology.
Global tech companies actively enrich their solutions with a RAG LLM. AWS (Amazon Web Services) is not the exception. At the end of 2019, the company released Amazon Kendra — an enterprise search service empowered with AI, ML, and NLP. Today, the solution can also perform semantic and contextual searches and provide the Retrieve API for the RAG use case.
Both fine-tuning and RAG are the approaches to LLM enhancement. The first option is focused on constant model training on smaller datasets to enable them to implement specific tasks, while the second one is aimed at extending the potential of LLMs by connecting them with external relevant information sources.
Here are the tools enriched with a RAG model (LLM):
- IBM Watsonx.ai (a platform for training, validating, and deployment of generative AI and foundation models);
- Meta AI Research (an academic AI laboratory that unites generation and retrieval while knowledge sharing);
- Hugging Face (an open-source AI community that provides a transformer plugging for RAG model generation).
The RAG approach was introduced by Meta in 2020 as an attempt to remove training overhead from the response generation process.
RAG-based LLMs retrieve relevant context from a vector database by applying similarity search. Unlike its age-old keyword-based counterpart, semantic search makes it possible to narrow down the query meaning and retrieve domain-specific knowledge. Weaviate belongs to vector databases.

Contacts
Feel free to get in touch with us! Use this contact form for an ASAP response.
Call us at +44 151 528 8015
E-mail us at request@qulix.com



Feel free to get in touch with us! Use this contact form for an ASAP response.
Call us at +44 151 528 8015
E-mail us at request@qulix.com
![]()
![]()
![]()